Updated Date: 07/07/2026
Disaster Recovery Best Practices
The BIG-IQ system uses high availability and zone awareness functions to maintain data collection device (DCD) operations even when a node or an entire data center goes down. DCDs in each data center are assigned to the appropriate zone. This zone awareness enables the system to manage the distribution of your data and maintain DCD operation in all but the most severe outages.
For a better understanding of how this process works, consider the following example. A hypothetical company named Acme has two data centers; one in Seattle and the other in Boston. Acme wants to ensure data reliability, and has set up these data centers so that if one goes offline, the DCD data it was receiving is routed to the other data center. To achieve this, Acme has an HA pair of BIG-IQ systems for viewing and managing the data, and six DCDs divided equally between the two data centers. Two BIG-IP devices are used to load balance data and configure Fraud Protection Services and Application Security Manager settings for both data centers.
The HA pair ensures that one BIG-IQ system is always available for managing configuration data. The standby system is available for viewing configuration data, and managing data. The DCDs are treated as one large cluster that is split between two sites. Each data node is replicated, so that if one goes down, or even if an entire data center goes down, the data is still available.
Important: The total number of DCDs should be an even number so that they can be split evenly between the data centers. This conformation makes it easier to configure zones.
Note: For optimum performance, F5 makes the following maximum round trip latency recommendations:
| For connections between these components | Round trip latency cannot exceed |
|---|---|
| between any two DCD or BIG-IQ devices in a DCD cluster | 75 ms. |
| between the BIG-IQ CM and the BIG-IP devices it manages | 250 ms. |
| between the managed BIG-IP devices and the DCDs that collect their data | 250 ms. |
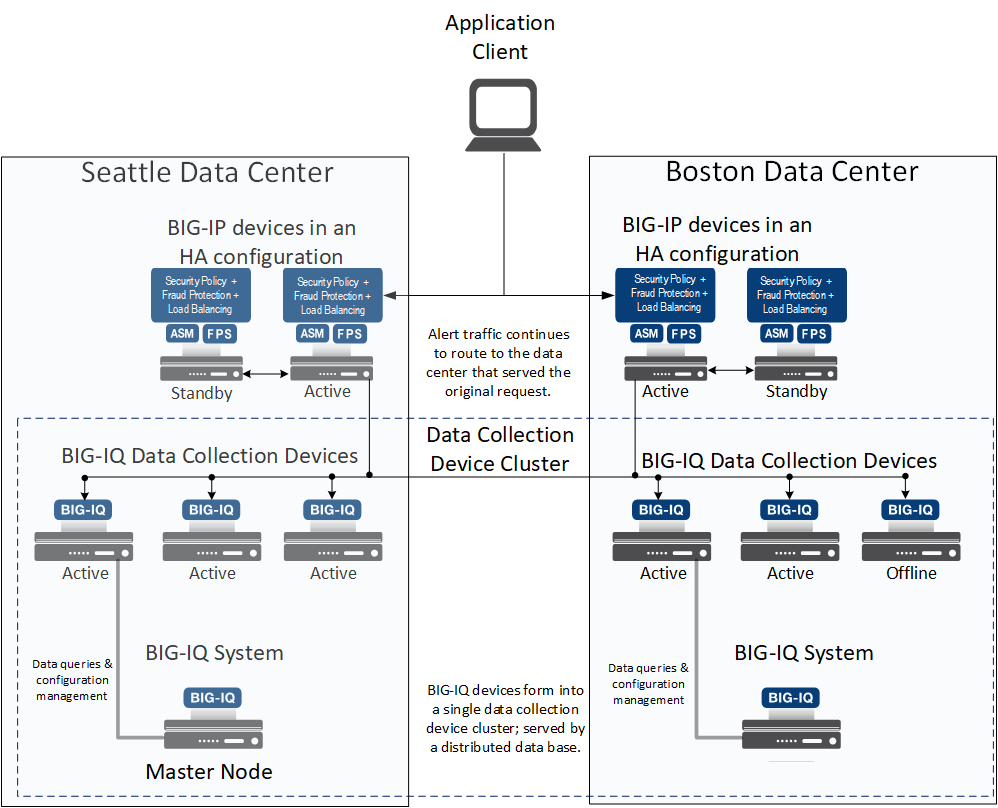
The DCD cluster logic that governs the distribution of data between your DCDs identifies one node in the cluster as the master node. The master node monitors the cluster health and manages the cluster operation. It is elected by the cluster, and can reside on any node. (The BIG-IQ system, however, does not store any data.) If a master node goes down, a new master is elected from among all the nodes in the cluster.
One parameter of special significance in determining the behavior of the data collection device (DCD) cluster is the minimum master eligible devices (MMED) setting. All of the devices in the cluster (including the primary and secondary BIG-IQ systems) are eligible to be the master device.
When a device is added or removed from the DCD cluster, the system performs a calculation to determine the optimum default value. You can override the default value to suit your requirements.
This setting determines how many DCDs in the cluster must be online for the cluster to continue to process alert data. If your goal is to keep operating regardless of device failures, it might seem like the obvious choice would be to set this number to as low a value as possible. However, you should keep in mind a few factors:
- The BIG-IQ system is counted as a device in the DCD cluster, so a cluster size of 1 does not make sense.
- Similarly, a cluster size of 2 (a DCD and the BIG-IQ console) is not a good idea. Because the DCD cluster logic uses multiple DCDs to ensure the reliability of your data, you need at least two logging devices to get the best data integrity.
- It might also seem like a good idea to set the MMED to a higher value (for example, one less than the number in the entire cluster), but actually, best practice is to not specify a value larger than the number of devices in one zone. If there is a communications failure, the devices in each zone compose the entire cluster, and if the MMED is set to a lower value, both clusters stop processing data.
Here are some of the most common failure scenarios that can occur to a data collection device cluster, and how the cluster responds to that scenario.
| What failed? | How does the cluster respond? |
|---|---|
| One of the data collection devices fails. | All alert data, including the data that was being sent to the failed node, is still available. When a node is added, removed, or fails, the cluster logic redistributes the data to the remaining nodes in the cluster. |
| The master node fails. | The cluster logic chooses a new master node. This process is commonly referred to as electing a new master node. Until the new master is elected, there may be a brief period during which alert processing is stopped. Once the new master is elected, all of the alert data is available. |
| All of the data collection devices in a zone fail. | Just as when a single data collection device fails, the cluster logic redistributes the data to the remaining nodes in the cluster |
This scenario is a little more complex than the case where data collection devices fail, so it needs a little more discussion to understand. However, it’s also much less likely to occur. The cluster behavior in this scenario is controlled by the Minimum Master Eligible Devices (MMED) setting. The default MMED setting is determined by a simple formula: the (total number of nodes / 2) + 1. This setting should handle most scenarios. Before you consider changing the default setting, you should learn more about how the Elasticsearch logic uses it. Refer to the article on discovery.zen.minimum_master_nodes in the Elasticsearch Reference, version 6.3 documentation.
You do not control which node is the master, but the master node is identified on the Cluster Settings tab of the BIG-IQ Data Collection Configuration page. Considering the two-data-center scenario discussed previously, let’s assume that the master node is in the Seattle data center. If communication goes down between the data centers, the Seattle data center continues to function as before, because with four nodes (the BIG-IQ system and three DCDs) it satisfies the MMED setting of 3. In the Boston data center, a new master node is elected because without communication between the two data centers, the Boston data center has lost communication with the master node. Since the Boston data center also has four master eligible nodes, it satisfies the MMED setting. The Boston data center elects a new master and forms its own cluster. So, once the two new master nodes are elected, BIG-IP devices in each data center send their alerts to the DCDs in their own cluster, and the master node in each zone controls that zone.
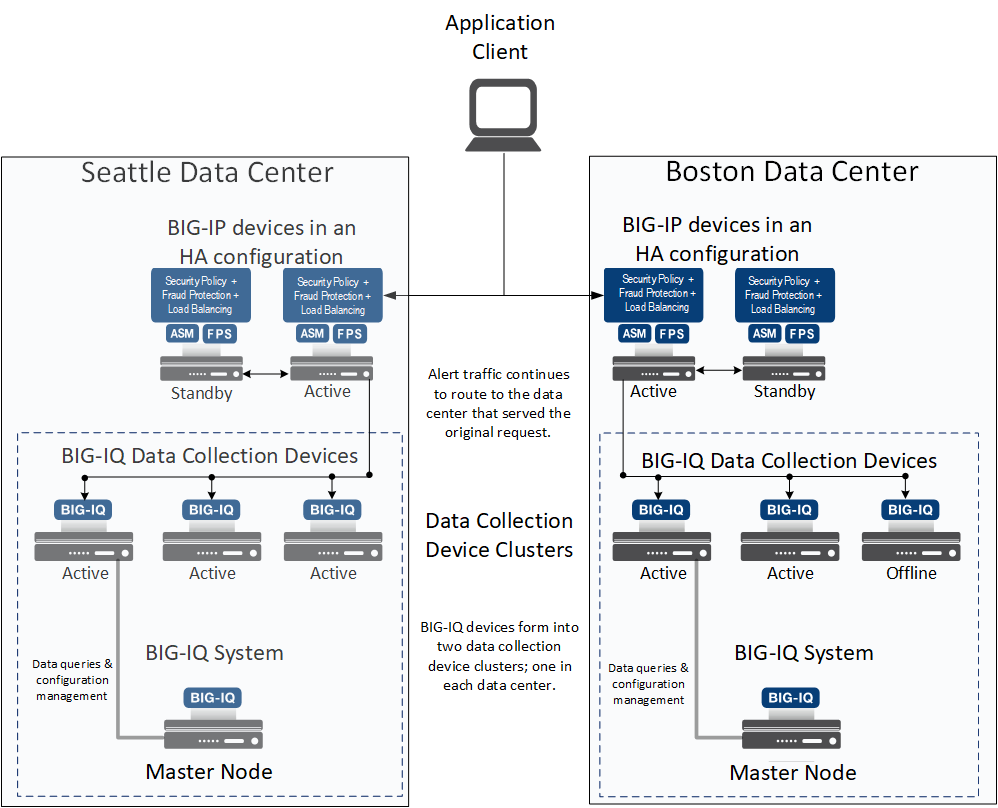
When communication resumes, the cluster that existed before the failure does not reform on its own, because both data centers have formed their own independent clusters. To reform the original cluster, you can restart the master node for one of the clusters. However, reforming the cluster without first doing a couple of precautionary steps is not generally the best practice because you will lose some data.
- If you decide to restart the master node in the Boston data center when communication is restored, the cluster logic sees that the Seattle data center already has an elected master node, so the Boston cluster joins the Seattle cluster instead of forming its own. The Seattle master node then syncs its data with the Boston nodes in the cluster. The data sync overwrites the Boston data with the Seattle data. The result is that Boston data received during the communication failure is lost.
- If you decide to restart the master node in the Seattle data center when communication is restored, the cluster logic sees that the Boston data center already has an elected master node, so the Seattle cluster joins the Boston cluster. The Boston master node then syncs its data with the nodes in the Seattle cluster. That data sync overwrites the Seattle data with the Boston data. The result is that Seattle data received during the communication failure is lost.
To preserve as much data as possible, F5 recommends that, instead of just reforming the original cluster by restarting one of the clusters, you perform these two precautionary steps.
- When a communication failure occurs, change the target DCDs for the BIG-IP devices in the zone that did not include the original master node (Boston, in our example) to one of the DCDs in the zone that housed the original master node (Seattle, in our example).
- When communication is restored, in the zone that did not include the original master node (Boston, in our example), use SSH to log in to the master node as
root, and then typebigstart restart elasticsearch, and press Enter. Restarting this service removes this node from the election process just long enough so that the original (Seattle) master node can be elected.
After you perform these two steps, all alerts are sent to nodes in the zone that contained the original master node. Then when communication is restored, the DCDs in the zone where the master node was restarted (Boston in our example) rejoin the cluster. The resulting data sync overwrites the Boston data with the Seattle data. The Seattle data center has the data that was collected before, during, and after the communications failure. The result is that all of the data for the original cluster is saved and when the data is synced, all alert data is preserved.
When you have data collection devices in multiple data centers, you can optimize your deployment to maintain data collection when some or all of the data collection devices in one data center fail. A few slight variations to the deployment process make it possible for you to take advantage of the BIG-IQ system’s zone awareness feature. The resulting data collection device (DCD) cluster deployment provides the optimum data collection performance in an outage scenario.
Note: In the user interface, a data center is identified by its zone name. The data center in Seattle and the zone named Seattle are the same thing.
-
Install and configure a BIG-IQ console node in both data centers.
-
Configure the two console nodes so that one is the HA primary and the other is the HA secondary.
-
For the console node configured as the HA primary, specify the zone in which that device resides.
-
Deploy the DCD in each data center.
-
On the primary console node, add all of the DCDs to the cluster. As you add devices, specify the zone name appropriate for the data center in which each node is physically located.
-
Initiate an HA failover of the primary BIG-IQ console to the secondary BIG-IQ console.
When the BIG-IQ HA primary fails over to the secondary, the logging configuration information propagates to both zones and a new primary is designated.
-
On the (newly designated) primary BIG-IQ console, specify the name of the zone in which that console resides.
-
Initiate an HA failover of the (new) primary BIG-IQ console to the secondary BIG-IQ console.
The BIG-IQ console that was originally the HA primary is once again the primary.
-
Set the minimum master capable devices on the primary console. To display the HA properties screen, click System > BIG-IQ HA and then select the device.
The Zone field is located at the bottom of the screen.
You can manage the minimum number of devices that must be available for the cluster to be considered operational. If the number of available devices is less than the value specified for the Minimum Master Eligible Devices, the cluster is deemed unhealthy.
-
From BIG-IQ, at the top of the screen, click System, then, on the left, click BIG-IQ DATA COLLECTION and then select BIG-IQ Data Collection Cluster.
The BIG-IQ Data Collection Cluster screen opens. On this screen, you can view summary status for the Data Collection Device (DCD) cluster and access the screens that you can use to configure the DCD cluster.
- Under SUMMARY, you can access screens detailing how much data is stored, as well as how the data is stored.
- Under CONFIGURATION, you can access the screens that control DCD cluster performance.
-
Under the screen name, click CONFIGURATIONCluster Settings**.
The Cluster Settings screen opens.
-
To change this setting, click Override.
The button text changes to Update.
-
In the Minimum Master Eligible Devices field, type or select the new minimum number of healthy devices for this DCD cluster, and click Update.
The system updates the setting.
-
When you are satisfied with the minimum number of devices setting, click Cancel to close the screen.
Before you do routine maintenance on a data collection device (DCD), there are a couple of steps you should perform to make sure the DCD cluster operation is not impacted.
-
On the BIG-IQ Data Collection Devices screen, remove the node from the DCD cluster.
The system recalculates and resets the Minimum Master Eligible Nodes setting.
-
If your DCD cluster configuration does not use the default value, override the Minimum Master Eligible Nodes setting to its previous value.
-
Perform the maintenance on the DCD.
-
Add the node back into the DCD cluster.
The system recalculates and resets the Minimum Master Eligible Nodes setting.
-
If your DCD cluster configuration does not use the default value, override the Minimum Master Eligible Nodes setting to its previous value.
Normally, you assign a Data Collection Device (DCD) to a zone as part of the initial setup for that device. But you can change the zone to which a DCD is assigned as needed.
-
From BIG-IQ, at the top of the screen, click System, then, on the left, click BIG-IQ DATA COLLECTION > BIG-IQ Data Collection Devices.
The BIG-IQ Data Collection Devices screen opens listing the DCDs in the cluster. The Services column lists the BIG-IP services monitored by each DCD. If no services are enabled for a DCD, this column displays Add Services instead.
-
Under Device Name, select the DCD that you want to revise.
-
On the DCD properties page, click Edit to display the Edit Zone popup.
- To use an existing Zone, select the zone you want to assign to this DCD and click Continue.
- To use a new Zone, select Create New, then type the name of the zone to want to create and assign to this DCD and click Continue.
-
Click Save & Close to close the DCD properties screen.
-
Use SSH to log in to DCD as
root. -
Type
bigstart restart elasticsearchand press Enter. -
Repeat the last three steps for each DCD that you want to move to this zone.
Note: As you run this command on each DCD, it momentarily stops processing DCD data, so the data routes to another node in the cluster and no data is lost.
You can now assign managed BIG-IP devices to this zone for data collection.