Applies To:
Show Versions
BIG-IP AAM
- 11.6.5, 11.6.4, 11.6.3, 11.6.2, 11.6.1
Overview: Acceleration policies
An acceleration policy is a collection of defined rule parameters that dictate how the BIG-IP system handles HTTP requests and responses. The BIG-IP system uses two types of rules to manage content: matching rules and acceleration rules. Matching rules are used to classify requests by object type and match the request to a specific acceleration policy. Once matched to an acceleration policy, the BIG-IP system applies the associated acceleration rules to manage the requests and responses.
Depending on the application specific to your site, information in requests can sometimes imply one type of response (such as a file extension of .jsp), when the actual response is a bit different (like a simple document). For this reason, the BIG-IP system applies matching rules twice: once to the request, and a second time to the response. This means that a request and a response can match to different acceleration rules, but it ensures that the response is matched to the acceleration policy that is best suited to it.
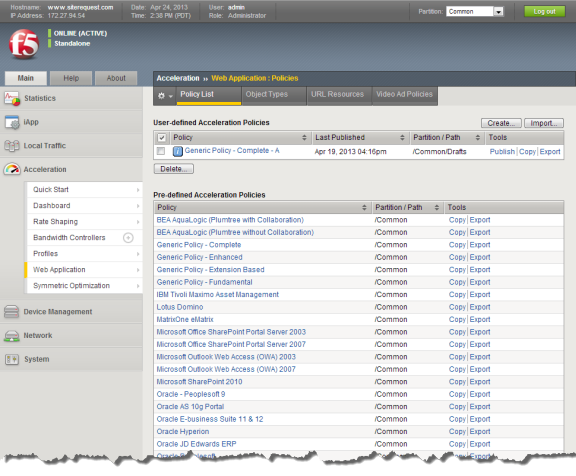
Types of acceleration policies
There are two types of acceleration policies that you can use to speed up the access to your web applications.
| Type of policies | Description |
|---|---|
| Predefined acceleration policies | The BIG-IP ships with several predefined acceleration policies that are optimized for specific web applications, as well as four non-application specific policies for general delivery. |
| User-defined acceleration policies | You can create a user-defined policy by either copying an existing policy and modifying or adding rules, or by creating a new acceleration policy and specifying all new rules. |
BIG-IP acceleration policies options
When configuring policies in a BIG-IP acceleration application, you can do one or more of the following tasks.
Predefined Policies
- Use a predefined policy. Predefined policies are available when you configure a BIG-IP acceleration application. You do not need to create them.
User-Defined Policies
- Create and use a user-defined policy by copying a predefined policy.
- Create and use a new user-defined policy
Acceleration policy selection
You can select a predefined acceleration policy that is associated with your specific application publisher or you can use one of the predefined generic acceleration policies. Both work well for most sites that use Java 2 Platform Enterprise Edition (J2EE) applications.
| Predefined Policy | Description |
|---|---|
| Generic Policy - Complete | This predefined acceleration policy is ideal for Apache HTTP servers, Internet Information Services (IIS) web servers, WebLogic application servers, and IBM Websphere Application Servers. HTML pages are cached and Intelligent Browser Referencing is enabled. |
| Generic Policy - Enhanced | This predefined acceleration policy is ideal for Apache HTTP servers, Internet Information Services (IIS) web servers, WebLogic application servers, and IBM Websphere Application Servers. HTML pages are cached and Intelligent Browser Referencing is enabled for includes. |
| Generic Policy - Extension Based | This predefined acceleration policy is ideal for High Performance policy for Ecommerce applications that uses File Extensions instead of mime-types. This application policy is ideal if response-based matching is not required. |
| Generic Policy - Fundamental | This predefined acceleration policy is ideal for Apache HTTP servers, Internet Information Services (IIS) web servers, WebLogic application servers, and IBM Websphere Application Servers. HTML pages are always proxied and Intelligent Browser Referencing is disabled. |
Customization of acceleration policies
If you have a unique application for which you cannot use a predefined acceleration policy, you can create a new, user-defined acceleration policy.
Before you can create a new acceleration policy, you need to analyze the type of traffic that your site's applications receive, and decide how you want the BIG-IP to manage those HTTP requests and responses. To help you do that, consider questions similar to the following.
- Which responses do I want the BIG-IP to cache?
- Are there responses for static documents that can remain in the system's cache for several days before being refreshed?
- Which responses are dynamic documents that the BIG-IP should refresh hourly?
- Are there responses that the BIG-IP should never cache?
After you decide how you want the BIG-IP to handle certain requests for your site, you can identify the HTTP data parameters that the BIG-IP uses to match requests and responses to the appropriate acceleration policies.
For example, the path found on requests for static documents might be different than the path for dynamic documents. Or the paths might be similar, but the static documents are in PDF format and the dynamic documents are Word documents or Excel spreadsheets. These differences help you specify matching rules that prompt the BIG-IP to match the HTTP request to the acceleration policy that will handle the request and the response most expeditiously.
Creation of user-defined policies
You can create a user-defined acceleration policy most efficiently by copying an existing acceleration policy and modifying its rules to meet your unique requirements. Alternatively, you can create a new user-defined acceleration policy and define each matching rule and acceleration rule individually.
When you copy or create an acceleration policy, the BIG-IP maintains that acceleration policy as a development copy until you publish it, at which time the BIG-IP creates a production copy. Only a production (published) copy of an acceleration policy is available for you to assign to an application. You can make as many changes as you like to the development copy of an acceleration policy without affecting current traffic to your applications.
Publication of acceleration policies
When you modify rules for a user-defined acceleration policy that is currently assigned to an application, the BIG-IP creates a development copy and continues to use the currently published (production) copy to manage requests. The BIG-IP acceleration manager uses the modified acceleration policy to manage traffic only after you publish it.
If you create a new acceleration policy, you must publish it before you can assign it to an application.
About the Acceleration Policy Editor role
You can use the Acceleration Policy Editor role to manage and customize acceleration policies for the BIG-IP. This role provides full access to acceleration features and functionality, and read-only access to all other BIG-IP features and functionality.
Acceleration policies exported to XML files
You can use the export feature to save an acceleration policy to an XML file. F5 Networks recommends that you use the export feature every time you change a user-defined acceleration policy, so that you always have a copy of the most recent acceleration policy. You can use this file for back up and archival purposes, or to provide to the F5 Networks Technical Support team for troubleshooting issues.
Overview: Policy Matching
The BIG-IP system provides the flexibility needed to accelerate Web applications by processing and caching specific HTTP requests and responses. BIG-IP acceleration policies determine how the system handles and matches each request and response. A Policy Tree, configurable in the Policy Editor screen, contains branch nodes and leaf nodes that comprise a BIG-IP acceleration policy.
Leaf nodes include all of the settings (such as cache lifetime settings or proxy settings) and matching rules that determine how similar requests are processed. Additionally, grouping multiple leaf nodes under a branch node enables them to inherit the branch node settings.
When a request is received, the type of requested content typically determines the settings needed to process the request. Because Content-Type and Content-Disposition headers only become available when the BIG-IP system receives a response, the BIG-IP system provides a matching abstraction for requests called content type to determine, based on the request’s URL and available headers, the probable or actual content type, as well as to simplify the matching rules. For example, by default, requests with an extension of .gif are given an object type of images that is used in the abstract content type, which is more convenient to use in matching rules. The mapping for each abstract content type is configured as an Identifier in the Object Types screen.
The predefined content types consist of a descriptive group name (such as documents) and an object type name (such as msword). Matching rules can require either or both parts to match, as preferred. Many of the default policies have a node for matching documents. Some use the object type abstraction and some use the URL extension.
You configure matching rules from the Matching Rules screen, and configure Acceleration Rules by choosing Acceleration Rules from the Matching Rules menu.
Matching rules for leaf nodes determine the nodes to which requests and responses apply. All matching rules for a node must match before it can be considered to be a candidate for a best match. If more than one candidate exists, resolution rules, based upon priority and precedence, determine the single best match.
Resolution rules when multiple nodes match
Sometimes, both precedence and priority can produce a match. When multiple nodes produce a match, the BIG-IP must determine the best match. In some instances, priority determines the best match, in others, precedence determines the best match, and in still others, both precedence and priority together determine the best match.
Priority 1: An exact path match
An exact path match is one where the value set for the path parameter ends with a question mark. For example, if you have a rule with a path parameter value of apps/srch.jsp?, the BIG-IP considers a request of http://www.siterequest.com/apps/srch.jsp?value=computers to be an exact match, and matches the request to the leaf node to which the rule belongs.
It is important to note that a path of / and /? are two different things. A path that includes a ? indicates that an exact match is required.
By default, a path that you provide for a policy is a prefix. For example, if you give a parameter the path, /a/b, the BIG-IP considers both of the following requests a match: http://www.siterequest.com/a/b?treat=bone and http://www.siterequest.com/a/b/c?toy=ball.
If you add a question mark to the parameter so that it is, /a/b?, the BIG-IP considers only http://www.siterequest.com/a/b?treat=bone to be a match, because the question mark indicates that an exact match is required.
Priority 2: A single extension node match
If no single exact path matches, but only one node matches the extension, the BIG-IP considers the request to be an exact extension match, or best match.
For example, if you have a request matching rule that specifies an extension of jpg, the BIG-IP considers the following request an exact extension match, and matches the request to the leaf node to which the rule belongs.
http://www.siterequest.com/images/down.jpg
Priority 3: A single path segment match
If no single node matches an exact path or exact extension, but only one node matches a path segment, the BIG-IP considers the request to be an exact path segment match, or best match.
Matching rules based on a path segment (the text between two slash marks) have third priority over other parameter matches. If a single path segment matches a path segment within the path, the BIG-IP matches the request to the leaf node to which the rule belongs.
For example, if you have a rule that specifies a path segment of a, the BIG-IP considers the following request an exact match, and matches the request to the leaf node to which the rule belongs.
http://www.siterequest.com/a/b?treat=bone
Priority 4: Multiple extension matches
If the request does not match a single path node, a single extension node, or a single path segment node, but multiple extension nodes match, the BIG-IP applies specific matching rules to determine the best match.
Matching rules based on multiple extension matches have a fourth priority over other parameter matches. If multiple extension matches occur, only the following rules apply.
| Parameter Match | Description |
|---|---|
| One matching node with a longer path | For example, if you have a rule that specifies an extension of
jpg, the rule matches request with the longest path, specifically Node 1
of the following. Node 1: http://www.siterequest.com/images/down.jpgNode 2: http://www.siterequest.com/down.jpg |
| Node that matches the most conditions, if multiple matching nodes have the same path length | For example, if you have two rules that specify the same path, but the second rule also
specifies a matching path segment, then the second rule matches the request to the leaf node
to which the rule belongs. In this example, Node 1 in the following is matched. Node 1: http://www.siterequest.com/images/down.jpg Path Segment: down(R1,2)Node 2: http://www.siterequest.com/images/down.jpg |
| Node with the lowest ordinal number, if multiple matching nodes have the same path length and number of conditions | For example, if you have two rules that specify the same path and include the same
number of conditions, then the node with the lowest ordinal number from the policy is
matched. In this example, Node 2 in the following is matched. Node 1: http://www.siterequest.com/apps/search.jsp? dog&cat&search=magicPath: /apps/search.jsp Path Segment: cat(L2,2) Node 2: http://www.siterequest.com/apps/search.jsp? dog&cat&search=magicPath: /apps/search.jsp Path Segment: dog(L2,1) |
Unmatched requests
If a request does not match a leaf node in the Policy Tree, there is an unmatched node in the Policy Tree, and the BIG-IP either uses a predefined accelerator policy that manages unmatched requests and responses, or sends the request to the origin web server for content.
It is important to keep in mind that for the BIG-IP to consider a request a match, the request must match all the matching rules configured for a leaf node. If a request matches all the rules for a leaf node, except for one, the BIG-IP does not consider it a match, and processes it as an unmatched request.
An example matching rule
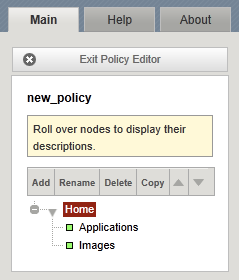
This topic provides information about how to configure an example matching rule. For this example site, you have three top-level nodes on the Policy Tree.
- Home. This branch node specifies the rules related to the home page.
-
Applications. This branch node specifies the rules related to the
applications for the site, with the following leaf nodes.
- Default. This leaf node specifies the rules related to non-search related applications.
- Search. This leaf node specifies the rules related to your site's search application.
- Images. This branch node specifies the rules related to graphics images.
You configure matching rules for this example Policy Tree, as described in the following table.
Overview: Policy Editor screen
From the Policy Editor screen, you can view the matching rules and acceleration rules for user-defined and predefined acceleration policies, as well as create or modify user-defined acceleration policies.
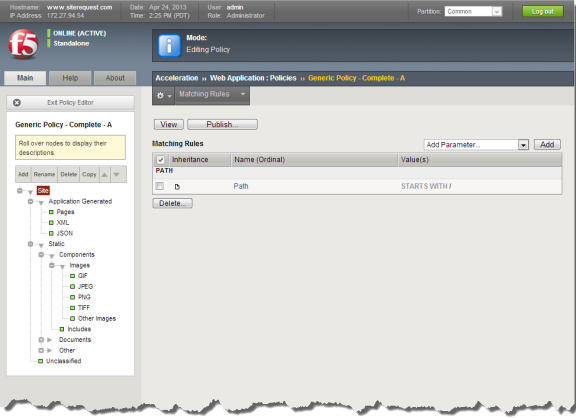 Policy Editor screen for an example acceleration policy
Policy Editor screen for an example acceleration policy
Policy Editor screen parts
There are three main parts to the Policy Editor screen.
| Part | Description |
|---|---|
| Policy Tree | Located on the left side of the Policy Editor screen, the Policy Tree contains branch
nodes and leaf nodes, which you can modify by using the function bar. A branch node
represents a group of content types (such as application generated or static) and each leaf
node represents specific content (such as images, includes, PDF documents, or Word
documents). The Policy Tree function bar includes the following options.
|
| Screen trail | Located above the Policy Editor menu bar, the screen trail displays (horizontally) the screens that you accessed in order to arrive at the current screen. You can click the name of a screen in the trail to move back to a previous location. |
| Policy Editor menu bar | Located below the screen trail, the Policy Editor menu bar contains a list from which you select Matching Rules (default) or Acceleration Rules. |
When you select Acceleration Rules, the acceleration rules menu bar appears.
Acceleration policy rule inheritance
The structure of the Policy Tree supports a parent-child relationship. This allows you to easily randomize rules. That is, because a leaf node in a Policy Tree inherits all the rules from its root node and branch node, you can quickly create multiple leaf nodes that contain the same rule parameters by creating a branch with multiple leaf nodes. If you override or create new rules at the branch node level, the BIG-IP reproduces those changes to the associated leaf nodes.
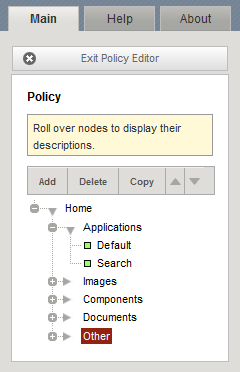
Nodes are defined as follows.
| Node | Description |
|---|---|
| Root node | The root node exists only for the purpose of inheritance; the BIG-IP does not perform matching against root nodes. The Policy Tree typically has only one root node, from which all other nodes are created. In the example figure, the root node is Home. What distinguishes a root node from a branch node is that a root node has no parent node. |
| Branch node | The branch nodes exist only for the purpose of propagating rule parameters to leaf nodes; the BIG-IP does not perform matching against branch nodes. In the example figure, the branch nodes are Applications, Images, Documents, Components, and Other. Branch nodes can have multiple leaf (child) nodes, as well as child branch nodes. |
| Leaf node | A leaf node inherits rule parameters from its parent branch node. The BIG-IP performs matching only against leaf nodes, and then applies the leaf node’s corresponding acceleration rules to the request. Leaf nodes are displayed on the Policy Tree in order of priority. If a request matches two leaf nodes equally, the BIG-IP matches to the leaf node with the highest priority. In the example figure, the leaf nodes that are displaying are Default and Search. |
Inheritance rule parameters
When you create a user-defined acceleration policy by copying an existing acceleration policy, you must determine from which branch node the acceleration policy is inheriting specific rules, and decide whether you want to change the rules at the leaf node or change the rules at the branch node. To determine inheritance for a rule parameter, view the rule parameter’s inheritance icon.
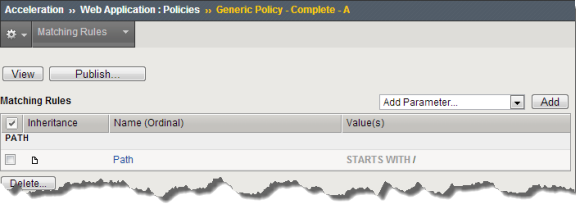
The following example figure illustrates matching rules for the Path and Header rule parameters for a particular leaf node.
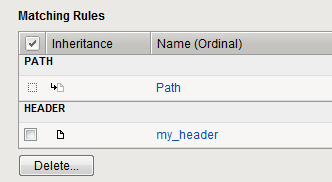 Inheritance example for Path and Header parameters
Inheritance example for Path and Header parameters
The arrow icon in the Inheritance column next to the Path parameter indicates this rule was inherited from the parent branch node. The inheritance icon next to the Header parameter does not have an arrow, indicating that the rule was not inherited; it was created locally at the leaf node.
Because the Header parameter rule is not inherited, you can delete the rule at the leaf node level. However, you cannot delete the Path parameter because it was inherited from the branch node. To delete the Path parameter rule, you must delete from its parent branch node.
For inherited rule parameters, you can determine the ancestor branch node by hovering the cursor over the inheritance icon. When placing the cursor on the inheritance icon next to Path, the branch node Home displays as the ancestor node, as illustrated in the following example figure.
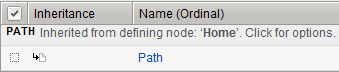
Inheritance rule parameters override
When you override an inherited setting for a rule, an override icon displays (the inheritance icon with a red X) next to the rule setting. To see the node where the option was overridden, place your cursor over the override icon.
For example, for the content assembly rule in the following example figure, all of the options are inherited from the branch node, except for the Enable Intelligent Browser Referencing To option. For this node, the rule was disabled at the leaf node. When hovering the cursor over the override icon, a message displays next to the Content Assembly Options menu.
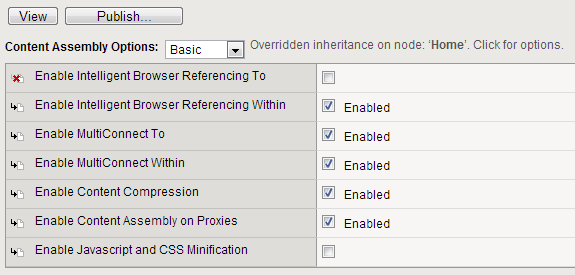
To see if the current leaf node inherited this overridden option, click the parent branch node and view its rules. In the following example figure, you see that there were no rule settings overridden at the parent branch, indicating the rule was inherited from the branch node, Home, and overridden at the leaf node.
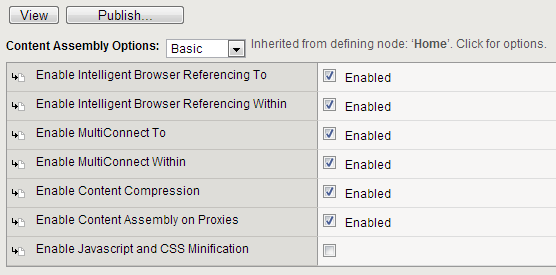
When you follow this rule back to its grandparent, you see the rule options are not inherited from any other node; they are set at the grandparent node and they are all enabled, as indicated in the following example figure.
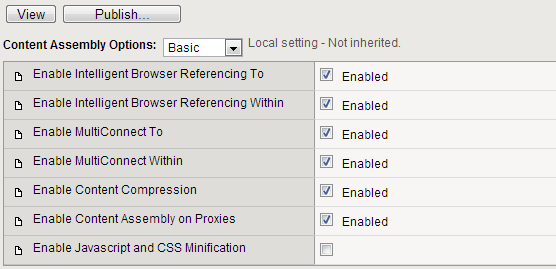
If you want to enable the content compression feature at the leaf node, you can use one of the following options.
- Override the inherited setting at the leaf node and select the Enable Content Compression check box.
- Cancel the override setting at the parent, so that the parent inherits the Enable Content Compression setting of the grandparent, and passes that setting to the leaf node.
Keep in mind that if you cancel the override setting at the grandparent branch node, you change the settings for all of the child leaf nodes, not just the leaf node you want to change.
Policy Tree modification for an acceleration policy
To customize a user-defined acceleration policy, you can modify matching rules and acceleration rules for the branch and leaf nodes. Or, you can add new branch and leaf nodes and associated matching and acceleration rules to the Policy Tree.
Overview: HTTP header parameters
Much of the BIG-IP device’s behavior is dependent on the configured rules associated with parameters in the HTTP request headers. Although important, the presence or value of HTTP response headers does not influence as many aspects of the BIG-IP’s behavior, because the BIG-IP receives HTTP response headers after performing certain types of processing.
When the BIG-IP receives a new request from a client, it first reviews the HTTP request parameters to match it to the relevant acceleration policy. After applying the associated matching rules, it sends the request to the origin web server for content.
Before sending a response to a client, the BIG-IP can optionally insert an X-WA-Info response header to track how it handled the request. You cannot change these informational headers, and they do not affect processing, however, they can provide useful information for evaluating your acceleration policies.
Requirements for servicing requests
To maintain high performance, the BIG-IP does not service an HTTP request unless the request meets the following conditions.
- The request includes an HTTP request header that is no larger than 8192 bytes, and in the first line, identifies its method, URI, and protocol.
- The method for the HTTP request header is a GET, HEAD, or POST method.
- The protocol for the HTTP request header is a HTTP/0.9, HTTP/1.0, HTTP/1.1, or HTTP/2.0.
- The HTTP post data on the request is no larger than 32768 bytes.
- If the request provides the Expect request header, the value is 100-continue.
- If the request provides the Content-Type request header, the value is application/x-www-form-urlencoded.
- The request includes a Host request header identifying a targeted host that is mapped to an origin server at your site.
If the HTTP Host request header is missing or does not have a value, the BIG-IP responds to the requesting client with a 400-series error message. If the request violates any of the other conditions, the BIG-IP redirects the request to the origin web servers for content.
About the HTTP request process
When a BIG-IP device receives an HTTP request that meets the required conditions, the BIG-IP processes the request in accordance with this sequence.
- The BIG-IP performs policy matching against the request and retrieves the associated acceleration rules.
- The BIG-IP evaluates the policy matching to a proxying rule, as follows:
Condition Process Request is matched to a proxying rule The BIG-IP sends the request to the origin web servers as required by the rule. Request is not matched to a proxying rule The BIG-IP attempts to retrieve the appropriate compiled response from cache. - The BIG-IP processes the attempt to retrieve the appropriate compiled response from cache, as
follows:
Condition Process No compiled response resides in cache The BIG-IP sends the request to the origin web servers for content. Compiled response resides in cache The BIG-IP searches for an associated content invalidations rule for the compiled response. - The BIG-IP processes the resultant content invalidations rule for the compiled response, as
follows:
Condition Process A content invalidations rule is triggered for the compiled response The BIG-IP compares the rule’s effective time against the compiled response’s last refreshed time. A content invalidations rule is not triggered The BIG-IP examines the compiled response’s TTL value to see if the compiled response has expired. - The BIG-IP processes the compiled response's last refresh time, as follows:
Condition Process The compiled response’s last refreshed time is before the content invalidations rule’s triggered time The BIG-IP sends the request to the origin web servers for content. The compiled response’s last refreshed time is after the content invalidations rule’s triggered time The BIG-IP examines the compiled response’s TTL value to see if the compiled response has expired. - The BIG-IP processes the compiled response’s TTL value, as follows:
Condition Process The compiled response has expired The BIG-IP sends the request to the origin web servers. The compiled response has not expired The BIG-IP services the request using the cached compiled response.
Requirements for caching responses
When the BIG-IP device receives a response from the origin web server, it inspects the HTTP response headers, applies the acceleration rules to the response, and sends the content to the client. To ensure the most effective performance, the BIG-IP does not cache a response from the origin server, or forward it to the originating requestor, unless it meets the following conditions.
- The request does not match to a do-not-cache proxying rule.
- The first line of the response identifies the protocol, a response code that is an integer value, and a response text. For example: HTTP/1.1 200 (OK).
- If the Transfer-Encoding response header is used on the response, the value is chunked.
- The response is complete, based on the method and type of data contained within the response,
as follows.
- HTML tags. By default, the BIG-IP considers a response in the form of an HTML page complete only if it contains both beginning and ending HTML tags.
- Content-Length response header. If a response is anything other than an HTML page, or if you have overridden the default behavior described in the previous bullet point, the BIG-IP considers content complete only if the response body size matches the value specified on the Content-Length response header.
- Chunked transfer coding. The BIG-IP accepts chunked responses that omit the final zero-length chunk. For information about chunked transfer coding, see section 3.6 in the HTTP/1.1 specification http://www.w3.org/Protocols/rfc2616/rfc2616-sec3.html#sec3.6.
If the BIG-IP receives a response from the origin server that does not conform to these conditions, it does not cache the response before sending it to the client.
About the HTTP responses process
When the BIG-IP receives a response from the origin web server, the BIG-IP performs the following actions.
- Inspects the HTTP response headers.
- Applies the acceleration rules to the response.
- Sends the content to the client.
Configuration of rules based on HTTP request headers
In most cases, the default values for the predefined acceleration policies are sufficient, but you can fine-tune the BIG-IP device's behavior by creating a user-defined acceleration policy and modifying the HTTP request data type parameters. When you specify or modify an HTTP data type parameter for an acceleration policy rule, you define specific HTTP data type parameter criteria that the BIG-IP uses to manage HTTP requests. When specifying parameter criteria, you designate the following information within a rule.
- Parameter identity. This can include one or more of the following criteria.
- Parameter type
- Parameter name
- Parameter location within the HTTP request
- Parameter value or state. This can include one or more of the following parameter
state and value.
- Parameter is present in the HTTP request and matches the defined value provided in the form of a regular expression.
- Parameter is present in the HTTP request and does not match the specified value provided in the form of a regular expression.
- Parameter is present in the HTTP request, but has no value (is an empty string).
- Parameter is not present in the HTTP request
- BIG-IP action. Where you specify the following criteria.
- Whether the BIG-IP performs an action on a match or a no match.
- The action that the BIG-IP performs, which is dictated by the rules in the associated acceleration policy.
For example, if you specify a rule that the BIG-IP performs an action when a request does not match a configured parameter, the rule triggers if the parameter in the request is a different value than you specified, or if the value is empty (null). The BIG-IP does not perform the specified action if the parameter does not appear in the request.
Specification of HTTP data type parameters for a rule
You cannot configure rules based on all HTTP data types parameters; you can only specify the parameters that the BIG-IP uses when processing HTTP requests.
The HTTP data type parameters that the BIG-IP uses when processing HTTP requests, are defined as follows.
Host
A rule that uses the host parameter is based on the value provided for the HTTP Host request header field. This header field describes the DNS name that the HTTP request is using. For example, for the following URL the host equates to HOST: www.siterequest.com.
http://www.siterequest.com/apps/srch.jsp?value=computers
Path
A rule that uses the path parameter is based on the path portion of the URI. The path is defined as everything in the URL after the host and up to the end of the URL, or up to the question mark, (whichever comes first). The following table shows examples of URLs and paths.
| URL | Path |
|---|---|
| http://www.siterequest.com/apps/srch.jsp?value=computers | /apps/srch.jsp |
| http://www.siterequest.com/apps/magic.jsp | /apps/magic.jsp |
Extension
A rule that uses the extension parameter is based on the value that follows the far-right period, in the far-right segment key of the URL path.
For example, in the following URLs, gif, jpg, and jsp are all extensions.
- http://www.siterequest.com/images/up.gif
- http://www.siterequest.com/images/down.jpg
- http://www.siterequest.com/apps/psrch.jsp;sID=AAyB23?src=magic
Query Parameter
A rule that uses the query parameter is based on a particular query parameter that you identify by name, and for which you provide a value to match against. The value is usually literal and must appear on the query parameter in the request, or a regular expression that matches the request’s query parameter value. The query parameter can be in a request that uses GET, HEAD, or POST methods.
You can also create a rule that matches the identified query parameter when it is provided with an empty value, or when it is absent from the request. For example, in the following URL the action query parameter provides an empty value.
http://www.siterequest.com/apps/srch.jsp?action=&src=magic
Unnamed Query Parameter
An unnamed query parameter is a query parameter that has no equal sign. That is, only the query parameter value is provided in the URL of the request. For example, the following URL includes two unnamed query parameters that have the value of dog and cat.
http://www.siterequest.com/apps/srch.jsp?dog&cat&src=magic
A rule that uses the unnamed query parameter specifies the ordinal of the parameter, instead of a parameter name. The ordinal is the position of the unnamed query parameter in the query parameter portion of the URL. You count ordinals from left to right, starting with 1. In the previous URL, dog is in ordinal 1 and unnamed, cat is in ordinal 2 and unnamed, and src is in ordinal 3 and named magic.
You can create a rule that matches the identified (unnamed) query parameter when it is provided with an empty value, or when it is absent from the request. For example, in the following URL, ordinal 1 provides an empty value.
http://www.siterequest.com/apps/srch.jsp?&cat&src=magic
In the following URL, ordinal 3 is absent (dog is in ordinal 1 and src is in ordinal 2).
http://www.siterequest.com/apps/srch.jsp?dog&src=magic
Path Segment
A rule that uses the path segment parameter identifies one of the following values.
- Segment key
- Segment parameter
Segment key. A segment is the portion of a URI path that is delimited by a forward slash (/). For example, in the path: /apps/search/full/complex.jsp, apps, search, full, and complex.jsp all represent path segments. Further, each of these values are also the segment key, or the name of the segment.
Segment parameter. A segment parameter is the value in a URL path that appears after the segment key. Segment parameters are delimited by semicolons. For example, magic, shop, and act are all segment parameters for their respective path segments in the following path.
/apps/search/full;magic/complex.jsp;shop;act
To specify segment parameters, you must also identify segment ordinals.
Segment ordinal. To specify a segment for a rule, you must provide an ordinal that identifies the location of the segment in the following path.
/apps/search/full;magic/complex.jsp;shop;act
You must also indicate in the rule, which way you are counting ordinals in the path: from the left or the right (you always count starting at 1). For the example shown, /full;magic, the ordinals for this path are as show in the following table.
| Ordinal | Numbering Selection |
|---|---|
| 3 | Numbering Left-to-Right in the Full Path |
| 2 | Numbering Right-to-Left in the Full Path |
Cookie
A rule that uses the cookie parameter is based on a particular cookie that you identify by name, and for which you provide a value to match against. Usually the value is literal and must appear on the cookie in the request, or a regular expression that must match the request’s cookie that appears on the cookie HTTP request headers. These are the same names you use to set the cookies, using the HTTP SET-COOKIE response headers.
You can also create a rule that matches when the identified cookie is provided with an empty string or when it is absent from the request. For example, in the following string, the following REPEAT cookie is empty.
COOKIE: REPEAT=
In the following string, the USER cookie is present and the REPEAT cookie is absent.
COOKIE: USER=334A5E4
User Agent
A rule that uses the user agent parameter is based on the value provided for the HTTP USER_AGENT in the request header, which identifies the browser that sent the request. For example, the following USER_AGENT request header indicates that the requesting browser is IE 5.01 running on Windows NT 5.0.
USER_AGENT: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
You do not typically base rules on the USER_AGENT request header, unless your site behaves differently depending on the browser in use.
Referrer
A rule that uses the referrer parameter is based on the value provided for the HTTP REFERER in the request header. (Note the misspelling of REFERER. This spelling is defined for this request header in all versions of the HTTP specification.)
This header provides the URL location that referred the client to the page that the client is requesting. That is, REFERER provides the URL that contains the hyperlink that the user clicked to request the page. For example, the following REFERER request header provides the referred URL of http://www.siterequest.com/.
REFERER: http://www.siterequest.com/
You do not typically base rules on the REFERER request header, unless you want your site’s behavior to be dependent on the specific referrer. For example, one implementation would be for sites that provide different branding for their pages based on the user’s web portal or search engine.
Protocol
A rule that uses the protocol parameter is based on whether the request uses the HTTP or HTTPS protocol. For example, the following URL uses the HTTP protocol.
http://www.siterequest.com/apps/srch.jsp?value=computers
The following URL uses the HTTPS protocol.
https://www.siterequest.com/apps/srch.jsp?value=computers
Method
A rule that uses the method parameter is based on whether the request used the GET, HEAD, or POST method.
Header
A rule that uses the header parameter is based on a particular header that you identify by name, and for which you provide a value to match against. You can use an HTTP request data type header parameter to create rules based on any request header, other than one of the recognized HTTP request data types.
The HTTP request data type header parameter you use can be standard HTTP request header fields such as AUTHORIZATION, CACHE-CONTROL, and FROM. They can also be user or acceleration defined headers in the form of a structured parameter.
Following are examples of HTTP request data type parameters.
- Accept: text/html, image/*
- Accept-Encoding: gzip
- Accept-Language: en-us
- CSP-Gadget-Realm-User-Pref: NM=5,PD=true,R=3326
The last header in the example depicts a structured parameter.
The format of a structured parameter in a request is similar to that used for a cookie, with a header name that you choose, followed by a series of name=value pairs separated by commas. The header name is not case-sensitive and in this structure, the semicolons (;) are special characters. The parser ignores anything after a semicolon until it reaches the subsequent comma. For example, following are valid header structured parameters.
- CSP-Global-Gadget-Pref: AT=0
- CSP-Gadget-Realm-User-Pref: NM=5,PD=true,R=3326
- CSP-User-Pref:
- E2KU=chi,E2KD=ops%u002esiterequest%u002enet,E2KM=chi
- CSP-Gateway-Specific-Config:
- PT-User-Name=chi,PT-User-ID=212,PT-Class-ID=43
- Standards: type=SOAP;SOAP-ENV:mustUnderstand="1",version=1.2
In the last line, the parser ignores SOAP-ENV:mustUnderstand="1", because it follows a semicolon. Since version=1.2 follows the command, the parser reads it as a name=value pair. If you have metadata that you want to include in the header, but want the BIG-IP to ignore, put it after a semicolon.
If you specify a header as a structured parameter when creating a rule, the BIG-IP module parses it into name=value pairs when it examines the request. If you do not specify it as a structured parameter, the BIG-IP processes it like a normal header, and treats everything after the colon (:) as the value. To define a header as a structured parameter when you are creating or editing a rule, you specify the name using the following syntax: headername:parmname, where headername is the name of the header and parmname is the name of the parameter with the value that you want to affect the rule.
Using the CSP-Global-Gadget-Pref header as an example, if you want the BIG-IP to evaluate the value for AT to determine if a configured rule should apply, specify the name of the header parameter as follows: CSP-Global-Gadget-Pref:AT.
If you want the BIG-IP to evaluate the entire string without assigning meaning to name=value pairs, specify the name of the header parameter as follows: CSP-Global-Gadget-Pref.
You can create a rule that matches when the identified header is provided with an empty value, or when it is absent from the request.
In the following example, the BIG-IP considers Standards:release, empty and considers Standards:SOAP-ENV absent, because it is ignored: Standards: type=SOAP;SOAP-ENV:mustUnderstand="1",release=,version=1.2.
Client IP
A rule that uses the client IP parameter is based on the IP address of the client making the request. The IP address, however, might not always be the address of the client that originated the request.
For example, if the client goes through a proxy server, the IP address is the IP address of the proxy server, rather than the client IP address that originated the request. If several clients use a specific proxy server, they all appear to come from the same IP address.
Configuration of rules based on HTTP response headers
After the BIG-IP receives a response from the origin web server, it performs the following processes.
- Classifies the response
- Applies associated acceleration policy rules
- Assembles the response
Response headers have no effect on application matching, variation, or invalidations rules. The BIG-IP evaluates response headers associated with caching after it compiles, but before it caches, the response. Once the BIG-IP begins the compilation and assembly process, it then examines existing response headers that influence assembly.
You can configure assembly, proxying, lifetime, or responses cached rules based on response headers.
Classification of responses
After the BIG-IP device receives a response from the origin server, and before it performs application matching, it classifies the response based on the object types that are defined on the Object Types screen. The BIG-IP bases this classification on the first item it finds, in the following order.
- The file extension in the file name field of the response's Content-Disposition header.
- The file extension in the extension field of the response's Content-Disposition header.
- The response's Content-Type header, unless it is an ambiguous MIME type.
- The request's path extension.
For example, if the extension in the file name field of the response's Content-Disposition header is empty, the BIG-IP looks at the response's Content-Disposition header's file extension in the extension field. If that has an extension, the BIG-IP attempts to match it to a defined object type. If there is no match, the BIG-IP assigns an object type of other and uses the settings for other. The BIG-IP examines the information in the Content-Type header only if there is no extension in the file name or extension fields of the Content-Disposition header.
If the BIG-IP finds a match to an object type, it classifies the response with that object type, group, and category, and uses the associated settings for compression. The object type and group under which the response is classified is also included in the X-WA-Info response header.
Once it classifies the response by object type, the BIG-IP appends it as follows: group.objectType. The BIG-IP then matches the response to a node of a Policy Tree in an acceleration policy (the first matching process was for the request), using the new content type. In many cases, this content type is the same as the content type for the request, and the BIG-IP matches the response to the same node as the request.
Unlike the HTTP request data types, you do not base a matching rule directly on the value of an HTTP response data type. Instead, you base the rule on the content type parameter that the BIG-IP generates, by specifying the regular expression that you want a request or response's content type to match, or not to match.
Application of association acceleration policy rules
The BIG-IP device compiles the response, and determines if it can cache it by looking for a responses cached rule for the node that matches the response. If the response is cacheable, the BIG-IP caches a copy of the response.
Assembly of responses
The BIG-IP device assembles responses using the following information.
- The assembly rules specified for the node that matches the response.
- The Enable Compression setting (configured from the Object Types
screen) for the object type under which the response was classified. The options for this
setting include the following.
- Policy Controlled. The BIG-IP uses the compression settings configured in the acceleration policy’s assembly rules.
- None. The BIG-IP never compresses the response. This option overrides the compression setting in the acceleration policy’s assembly rules. Select this option only if you want the BIG-IP to ignore assembly rules for the specified object type.
Regular expressions and meta tags for rules
When the BIG-IP performs pattern matching based on regular expressions, it assumes all regular expressions are in the form of ^expression$, even if you do not explicitly set the beginning of line (^) and end of line ($) indicators. For substring searches, you enter *expression.* as a regular expression.
The string that the BIG-IP matches is dependent on the HTTP data type for which you are providing the regular expression. Before the BIG-IP attempts to match information in an HTTP request to the HTTP request data type parameters, it translates any escaped characters (such as %2F or %2E) back to their regular form, such as (/ or .,).
Management of Cache-Control response headers
The HTTP Cache-Control version 1.1 header specification identifies general-header field directives for all caching mechanisms along the request/response chain, and is used to prevent caching behavior from adversely interfering with the request or the response. (For additional information, see sections 13 and 14 of the HTTP/1.1 specification at http://www.w3.org/Protocols/rfc2616/rfc2616.html.)
Directives can appear in response or request headers, and certain directives can appear in either type of header. The HTTP Cache-Control general-header field directives typically override any default caching algorithms.
The origin web server’s cache response directives are organized in two groups: no-cache and max-age.
Cache-Control: no-cache directives
By default, the majority of the BIG-IP’s acceleration policies are configured to cache responses and ignore the following HTTP Cache-Control header’s no-cache directives.
- Pragma: no-cache
- Cache-Control: no-cache
- Cache-Control: no-store
- Cache-Control: private
You can configure the BIG-IP to honor no-cache directives. However, doing so can result in a noticeable increase in the traffic sent to the origin web server, depending on how many users send no-cache directives in requests.
Cache-Control: max-age directives
The BIG-IP system uses the HTTP Cache-Control header's max-age or s-maxage directives to determine the TTL values for compiled responses, only when the Honor Headers From Origin Web Server check box is selected. It uses combinations of the max_age and s_maxage settings for Origin Web Server Headers as selected (either one or both). If the Honor Headers From Origin Web Server settings are not configured, then the BIG-IP system uses the WebAccelerator Cache Settings Maximum Age value.
X-WA-Info response headers
Before sending a response to a client, the BIG-IP can optionally insert an X-WA-Info response header that includes specific codes describing the properties and history of the object. The X-WA-Info response header is for informational purposes only and provides a way for you to assess the effectiveness of your acceleration policy rules.
Following is an example of an X-WA-Info header.
X-WA-Info: [V2.S11101.A13925.P76511.N13710.RN0.U3756337437].[OT/images.OG/images]
The code is divided into fields by the period ( . ) delimiter. Each field begins with a letter code, followed by one or more letters or numbers. The object type and group under which the response is classified are also included in the X-WA-Info response header.
The object type is preceded by OT and the group is preceded by OG, as in the following example.
[OT/msword.OG/documents]
When you enable the X-WA-Info Header setting for an application, the following tasks describe how to view X-WA-Info response headers.
- Perform a packet capture of the page.
- Using an HTTP viewer utility like HttpWatch, HTTP Analyzer, or Live Headers.
- Using the Request Logging profile.
X-WA-Info response header in a symmetric deployment example
Typical X-WA-Info header in a symmetric deployment
| Condition | Description |
|---|---|
| Condition 1 |
|
| Condition 2 | The cache is cleared on the Remote device but not on the Central device, causing the Central device to issue a 200 OK response to the Remote device |
Sequence of X-WA-Info response header for symmetric devices
The following sequence shows the way in which the X-WA-Info response header updates in a symmetric deployment, starting with a request for new content on an empty cache with a lifetime of 2 seconds.
A first request is initiated for creation of a positive cache entry on both devices (a 200 OK response from the origin web server).
X-WA-Info: [Central].[V2.S10201.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.0].[O/0.3].[EH5/34].[DH1/0].[C/P] [Remote].[V2.S10201.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.2].[O/0.3].[EH1/0].[DH1/0].[C/P]A second request is initiated for caching of content on both devices (again, a 200 OK response from the origin web server).
X-WA-Info: [Central].[V2.S10201.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.1].[O/0.3].[EH6/14].[DH3/3].[C/D] [Remote].[V2.S10201.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.3].[O/0.3].[EH3/1].[DH3/1].[C/D]A third request is initiated once the objects are in the cache on both devices. The content is served from the Remote device's cache, and content is not proxied to the origin web server.
X-WA-Info: [Central].[V2.S10201.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.1].[O/0.3].[EH6/14].[DH3/3].[C/D] [Remote].[V2.S11101.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.4].[O/0.3].[EH2/68].[DH1/2].[C/D]Observe that the Central device's X-WA-Info header continues to use an S code of S10201.
A fourth request is initiated for the content that is now expired. The content is expired on both devices, and a conditional GET request is sent to the origin web server.
X-WA-Info: [Central].[V2.S10201.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.1].[O/0.3].[EH8/14].[DH3/3].[C/D] [Remote].[V2.S10232.A53316.P67996.N37551.RN0.U3955110987]. [OT/jpeg.OG/images].[P/0.4].[O/0.3].[EH2/71].[DH1/6].[C/D]Again, the Central device's X-WA-Info header uses an S code of S10201. The Central device is showing the S code from the last 200 OK response delivered to the Remote device by the Central device.
V code
The V code is the first field of the X-WA-Info response header. This field code indicates the version of the X-WA-Info response header code used in the BIG-IP software.
| V code | Description |
|---|---|
| V2 | Version 2 of the X-WA-Info response header code, used in BIG-IP version 11.3 software. |
S code
The S code is the second field of the X-WA-Info response header. This field code indicates whether the object in the HTTP response was served from the system's cache, or was sent to the original web server for content.
A code
The A code is the third field of the X-WA-Info response header, and identifies to which application the BIG-IP matched the request. This helps you determine which acceleration rules the BIG-IP applied to the request.
P code
The P code is the fourth field of the X-WA-Info response header, and it indicates the acceleration policy that the BIG-IP applied to the request.
N code
The N code is the fifth field of the X-WA-Info response header, and it identifies the application match of a request to an acceleration policy. The request node ID matches the policy node ID.
RN code
The RN code is the sixth field of the X-WA-Info response header, and it identifies the application match of a response to an acceleration policy. The BIG-IP can perform response-based application matching against MIME types in a response, or by matching attachment file name extensions. Request-based application matching against extensions in the URL path is not considered a response application match; however, a request application match appears in the N field.
A 0 (zero) RN code in the X-WA-Info response header indicates that the BIG-IP response matching did not override the decision made in the initial request match (N-code), and that the initial request match and the response match are the same. A nonzero RN code in the X-WA-Info response header indicates that the response matching overrode the decision made in the initial request match, and that the initial request match and the response match are different.
Reference summary for HTTP data
This section provides HTTP reference data, including request data type paramenters, response status codes, S code definitions.
HTTP request data type parameters
This table describes the HTTP request data type parameters and respective rules.
| Parameter | Matching Rules | Variation Rules | Assembly Rules | Proxying Rules | Invalidations Rules |
|---|---|---|---|---|---|
| Host | x | x | x | x | |
| Path | x | x | |||
| Extension | x | x | |||
| Query parameter | x | x | x | x | x |
| Unnamed query parameter | x | x | x | x | x |
| Path segment | x | x | x | x | x |
| Cookie | x | x | x | x | |
| User Agent | x | x | x | x | |
| Referrer | x | x | x | x | |
| Protocol | x | x | x | x | |
| Method | x | x | x | x | |
| Header | x | x | x | x | |
| Client IP | x | x | x | x | |
| Content Type | x |
Response status codes
This table describes HTTP response codes that you can add in addition to the default 200, 201, 203, or 207 response codes.
| Response code | Definition |
|---|---|
| 200 | OK. The request is satisfactory. |
| 201 | Created. The requested resource (server object) was created. |
| 203 | Non-Authoritative Information. The transaction was satisfactory; however, the information in the entity headers came from a copy of the resource, instead of an origin web server. |
| 207 | Multi-Status (WebDAV). The subsequent XML message might contain separate response codes, depending on the number of sub-requests. |
| 300 | Multiple Choices. The requested resource has multiple possibilities, each with different locations. |
| 301 | Moved Permanently. The requested content has been permanently assigned a new URI. The origin web server is responding with a redirect to the new location for the content. |
| 302 | Found. The requested content temporarily resides under a different URI. The redirect to the new location might change. |
| 307 | Temporary Redirect. The requested content temporarily resides under a different URI. The redirect to the new location might change. |
| 410 | Gone. The requested content is no longer available and a redirect is not available. |
S code definitions
This table describes the S codes, the first field of the X-WA-Info response header, which indicates whether the object in the HTTP response was served from the system's cache, or was sent to the original web server for content.
| Code | Definition | Description |
|---|---|---|
| SO | Response was served from an unknown source. | Indicates that the BIG-IP was unable to determine if a response was served from cache or sent to the origin web server for content. |
| S10101 | Response was served from cache. | Indicates that the content was served from cache, that the content is usually dynamic, and that the content might or might not be assembly processed. |
| S10201 | Response was served from the origin web server, because the request was for new content. | When the BIG-IP receives a request for new content, it sends the request to the origin web server and caches the content before responding to the request. Future requests for this content are served from cache. |
| S10202 | Response was served from the origin web server, because the cached content had expired. | When the BIG-IP receives a request for cached content that exceeds a lifetime rule’s Maximum Age setting, it revalidates the content with the origin web server (which responds with a 200 (OK) status code). After revalidating the content, the BIG-IP serves requests from cache, until the Maximum Age setting is once again exceeded. |
| S10203 | Response was served from the origin web server, as dictated by an acceleration policy rule. | When the BIG-IP matches a request to a node with a proxying rule set to Always proxy requests for this node, the BIG-IP sends that request to the origin web server, rather than serving content from cache. |
| S10204 | Response was served from the origin web server, because of specific HTTP or web service methods. | If the BIG-IP receives a request that contains an HTTP no-cache directive, the BIG-IP sends the request to the origin server and does not cache the response. In addition, the BIG-IP does not currently support some vendor-specific HTTP methods (such as OPTIONS) and some web services methods (such as SOAP). The BIG-IP sends requests containing those methods to the origin web server for content. |
| S10205 | Response was served from the origin web server because the cached content was invalidated. | You can perform a cache invalidation manually, through direct XML messaging over HTTPS on port 8443, or with an acceleration rule setting. After the BIG-IP invalidates cache and retrieves new content from the origin web server, it stores the response and serves future requests from cache. |
| S10206 | Response was served from the origin web server, because the content cannot be cached. | If a response cannot be cached, for example, because the content is private or the header is marked as no-store, the BIG-IP includes this code in the response to the client. |
| S10232 | Response was served from cache, after sending a conditional GET request to the origin web server and receiving a response indicating that the expired cached content is still valid. | If an acceleration rule prompts the BIG-IP to expire content, it sends the next request to the origin web server. If the origin web server indicates that the cached content has not changed (responding with a 304 (Not Modified) status code), the BIG-IP includes this code in the response to the client. |
| S10413 | Response bypassed the BIG-IP. | When a request includes an Expect: 100-continue header, that request and its response bypass the BIG-IP, which responds with an X-WA-Info header that includes an S10413 field code. |
| S11101 | Response was served from cache. | Indicates that the content was served from cache, that the content is static, and that the content came directly from cache without assembly processing by the BIG-IP system. This is the most efficient and fastest response method. |
HTTP data types for regular expression strings
This table describes the HTTP data types that are supported by the BIG-IP for regular expression strings.
| HTTP data type | Definition | Example |
|---|---|---|
| host | The value set for the HTTP Host request header |
HOST: www.siterequest.com
The BIG-IP matches the example HTTP Host request header to the string www.siterequest.com. |
| path | The value set for the path portion of the URI |
http://www.siterequest.com/apps/search.jsp?value=computer
For the example URI, the BIG-IP matches the string /apps/search. |
| extension | The value set for the extension portion of the URI |
http://www.siterequest.com/apps/search.jsp?value=computer
For the example URI, the BIG-IP matches the string jsp. |
| query parameter | The value set for the identified query parameter |
http://www.siterequest.com?action=display&PDA
The BIG-IP matches the example value set for the action query parameter to the string display. A query parameter is matched against the requested URL, or a Content-Type header's URL encoded string in the body of a POST method. If the specified query parameter appears one or more times in the request, all instances will be matched. |
| unnamed query parameter | The value set for the identified query parameter |
http://www.siterequest.com?action=display&PDA
If the value set for the unnamed query parameter in ordinal 2 is this URI, the BIG-IP matches the string PDA. An unnamed query parameter is matched against the requested URL, or a Content-Type header's URL encoded string in the body of a POST method. The ordinal specifies the left-to-right position of the parameter to match. |
| path segment | The name of the segment key or the value set for the segment parameter, depending on what you identify for the match |
http://www.siterequest.com/apps;AAY34/search.jsp?
value=computer
If you identify the path segment in ordinal 1 for the full path (counted from left-to-right), then you have identified the segment key in the URL, and the BIG-IP matches the string apps. Path segments are matched against the ordered segments, separated by a virgule (/) and terminated by the first question mark (?) or octothorpe (#) in the URL |
| cookie | The value set for the identified cookie |
COOKIE: SESSIONID=TN2MM1QQL
The BIG-IP matches the string TN2MM1QQL. |
| user agent | The value set for the HTTP USER_AGENT request header |
USER_AGENT: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT
5.0)
The BIG-IP matches the string Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0). |
| referrer | The value set for the HTTP REFERER request header |
REFERER:
http://www.siterequest.com?action=display
The BIG-IP matches the string http://www.siterequest.com?action=display. |
| protocol | The protocol used for the request |
http://www.siterequest.com
The BIG-IP matches the string http. |
| method | The value set for the identified method |
GET /www/siterequest/index.html
The BIG-IP matches the string /www/siterequest/index.html. |
| header | The value set for the identified header | Accept-Encoding: gzip
The BIG-IP matches the string gzip . |
| client ip | The source IP address for the HTTP request |
CLIENT-IP: 192.160.10.3
The BIG-IP matches the string 192.160.10.3. |
Max age value for compiled responses
This table describes the max age values for compiled responses.
| Priority | Directive | Description |
|---|---|---|
| 1 | Cache-Control: s-maxage | The BIG-IP bases the TTL on the current time, plus the value specified for the HTTP Cache-Control header’s s-maxage directive. Values for this directive are expressed in seconds. |
| 2 | Cache-Control: max-age | The BIG-IP bases the TTL on the current time, plus the value specified for the HTTP Cache-Control header’s max-age directive. Values for this directive are expressed in seconds. |
| 3 | Expires | The BIG-IP uses the TTL provided for HTTP Cache-Control header’s entity-header field. Values for this field are expressed in Coordinated Universal Time (UTC time). To avoid caching issues, the BIG-IP must be properly synchronized with the origin web server. For this reason, F5 Networks recommends that you configure a Network Time Protocol (NTP) server. |
| 4 | Last-Modified | The BIG-IP bases this TTL by using the formula TTL =
curr_time + ( curr_time - last_mod_ time ) *
last_mod_factor. In this formula, the variables are defined as follows:
|
Meta characters
This table describes the meta characters that are supported by the BIG-IP for pattern matching.
| Meta character | Description | Example |
|---|---|---|
| . | Matches any single character. | |
| ^ | Matches the beginning of the line in a regular expression. The BIG-IP assumes that the beginning and end of line meta characters exist for every regular expression it sees. | |
| $ | Matches the end of the line. The BIG-IP assumes that the beginning and end of line meta characters exist for every regular expression it sees. |
The expression G.*P.* matches:
A pattern starting with the * character is the same as using .* For example, the BIG-IP interprets the following two expressions as identical.
|
| * | Matches zero or more of the patterns that precede it. | |
| + | Matches one or more of the patterns that precede it. |
The expression G.+P.* matches:
Do not begin a pattern with the + character. For example, do not use +Plan. Instead, use .+Plan. |
| ? | Matches none, or one of the patterns that precede it. |
The expression G.?P.* matches:
Do not begin a pattern with the ? character. For example, do not use ?Plan. Instead, use .?Plan. |
| [...] | Matches a set of characters. You can list the characters in the set using a string made of the characters to match. | The expression C[AHR] matches:
You can also provide a range of characters by using a dash. For example, the expression AA[0-9]+ matches:
It does not, however, match AAB2. To match any alphanumeric character, both upper-case and lower-case, use the expression [a-zA-Z0-9]. |
| [^...] | Matches any character not in the set. Just as with the character, [...], you can specify the individual characters, or a range of characters by using a dash (-). |
The expression C[^AHR].* matches:
The expression C[^AHR].*, however, does not match:
|
| (...) | Matches the regular expression contained inside the parenthesis, as a group. | The expression AA(12)+CV matches:
|
| exp1 exp2 | Matches either exp1 or exp2, where exp1 and exp2 are regular expressions. | The expression AA([de]12|[zy]13)CV matches:
|
Advanced Debug settings for General Options
For the General Options list, this table describes Advanced controls for Debug Options.
| Advanced control | Default | Description |
|---|---|---|
| X-WA-Info Header | None | This setting is used for troubleshooting purposes. You should not change
this setting unless instructed to do so by an F5 Network Technical Support Engineer.
|




