Applies To:
Show Versions
BIG-IQ Centralized Management
- 5.4.0
How does a data collection device cluster deal with disaster recovery scenarios?
The BIG-IQ® system uses high availability and zone awareness functions to maintain data collection device operations even when a node or an entire data center goes down. DCDs in each data center are assigned to the appropriate zone. This zone awareness enables the system to manage the distribution of your data and maintain DCD operation in all but the most severe outages.
For a better understanding of how this process works, consider the following example. A hypothetical company named Acme has two data centers; one in Seattle and the other in Boston. Acme wants to ensure data reliability, and has set up these data centers so that if one goes offline, the DCD data it was receiving is routed to the other data center. To achieve this, Acme has an HA pair of BIG-IQ console nodes for viewing and managing the data, and six DCDs divided equally between the two data centers. Two BIG-IP® devices are used to load balance data and configure Fraud Protection Services and Application Security Manager™ settings for both data centers.
The HA pair ensures that one BIG-IQ console node is always available for managing configuration data. The standby console is available for viewing configuration data, and managing data. The DCDs are treated as one large cluster that is split between two sites. Each data node is replicated, so that if one goes down, or even if an entire data center goes down, the data is still available.
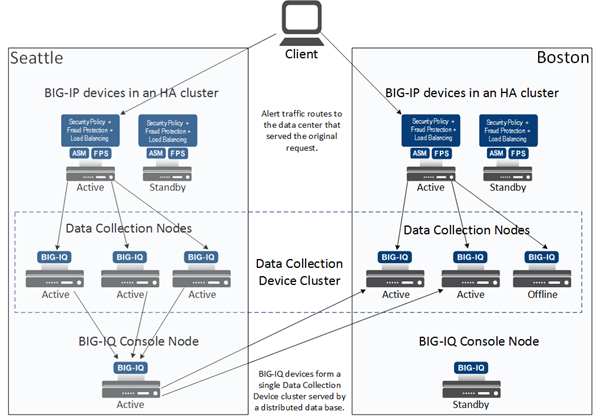
Two data centers, one DCD cluster example
The DCD cluster logic that governs the distribution of data between your DCDs identifies one node in the cluster as the master node. The master node monitors the cluster health and manages the cluster operation. It is elected by the cluster, and can reside on any node, including a console node. (Console nodes however, do not store any data). When the master node goes down, a new master is elected from among all the nodes in the cluster.
How is data handled when DCDs fail?
- One of the DCDs fails. Alert data is automatically routed to another DCD in the zone.
- The master node fails. The cluster logic chooses a new master node. This process is commonly referred to as electing a new master node.
- All of the DCDs in a zone fail. BIG-IP devices route their data to DCDs in the other zone.
How is data handled when communication between the two data centers fails?
This scenario is a little more complex and needs a little more detail to understand. It's also much less likely to occur. In the two data center DCD cluster scenario referenced previously, there is one master node located in one of the two data centers. The admin doesn't control which node is the master, but the master node is identified on the Logging Configuration page. For this example, let's assume that the master node is elected in the Seattle data center. If communication goes down between the data centers, the Seattle data center continues to function as before. In the Boston data center, a new master node is elected because without communication between the two data centers, each center forms its own DCD cluster. So, initially, BIG-IP devices in both data centers are sending data to the DCDs in their clusters, and a master node in each zone is controlling that zone.
When communication is resumed, the original cluster reforms and the master node from one of the zones is re-elected. The master node then syncs its data with the (new) nodes in the cluster. This data sync overwrites the data on the new nodes. If the Boston node is elected, its data (which only includes data collected during the communications failure) overwrites the data on the Seattle node (this means that most of the data for the cluster is lost). The Seattle data set includes both the data collected from before, and from during the communications failure. To prevent overwriting the more comprehensive data set and losing logging data, you can perform two precautionary steps.
- When a communication failure occurs, change the target DCDs for BIG-IP devices in the zone that did not include the original master node (Boston, in our example) to one of the DCDs in the other zone.
- When communication is restored, in the zone that did not include the original master node (Boston in our example), use SSH to log in to the master node as root, then type bigstart restart elasticsearch , and press Enter. Restarting this service removes this node from the election process just long enough so that the original master node can be elected.
The result is that during the failure, all data is sent to nodes in the zone that contained the original master node. Then when communication is restored, the DCDs in the zone in which the master node was restarted rejoin the cluster, and the data is synced to all of the DCDs. All data is preserved.
How does the minimum master eligible devices setting work?
One parameter of special significance in determining the behavior of the data collection device (DCD) cluster is the minimum master eligible devices (MMED) setting. All of the devices in the cluster (including the primary and secondary console devices) are eligible to be the master device.
When a device is added or removed from the DCD cluster, the system performs a calculation to determine the optimum default value. You can override the default value to suit your requirements.
This setting determines how many DCDs in the cluster must be online for the cluster to continue to process alert data. If your goal is to keep operating regardless of device failures, it would seem like the obvious choice would be to set this number to as low a value as possible. However, you should keep in mind a couple of factors:
- The BIG-IQ® console is counted as a device in the cluster, so a cluster size of 1 does not make sense.
- Similarly, a cluster size of 2 (a DCD and the BIG-IQ console) is not a good idea. Because the DCD cluster logic uses multiple DCDs to ensure the reliability of your data, you need at least two logging devices to get the best data integrity.
- It might also seem like a good idea to set the MMED value to a higher value (for example, one less than the number in the entire cluster), but actually, best practice is to not specify a value larger than the number of devices in one zone. If there is a communications failure, the devices in each zone compose the entire cluster, and if the MMED is set to a lower value, both clusters would stop processing data.
How is alert data handled when data collection devices fail?
Here are some of the most common failure scenarios that can occur to a data collection device cluster, and how the cluster responds to that scenario.
| What failed? | How does the cluster respond? |
|---|---|
| One of the data collection devices fails. | All alert data, including the data that was being sent to the failed node, is still available. When a node is added, removed, or fails, the cluster logic redistributes the data to the remaining nodes in the cluster. |
| The master node fails. | The cluster logic chooses a new master node. This process is commonly referred to as electing a new master node. Until the new master is elected, there may be a brief period during which alert processing is stopped. Once the new master is elected, all of the alert data is available. |
| All of the data collection devices in a zone fail. | Just as when a single data collection device fails, the cluster logic redistributes the data to the remaining nodes in the cluster |
How is data handled when communication between the two data centers fails?
This scenario is a little more complex than the case where data collection devices fail and needs a little more discussion to understand. However, it's also much less likely to occur. The cluster behavior in this scenario is controlled by the MMEN setting. In a two data center data collection device (DCD) cluster scenario, the MMEN setting is 3 and there is one master node located in one of the two data centers. The admin doesn't control which node is the master, but the master node is identified on the Logging Configuration screen. For this example, let's assume that the master node is in the Seattle data center. If communication goes down between the data centers, the Seattle data center continues to function as before because with four nodes (the console and three DCDs) it satisfies the MMEN setting of 3. In the Boston data center, a new master node is elected because without communication between the two data centers, communication with the master node is lost. Since there are also four master eligible nodes in the Boston data center, it satisfies the MMEN setting too. The Boston data center elects a new master and forms its own cluster. So, initially, BIG-IP® devices in both data centers are sending alerts to the DCDs in their clusters, and a master node in each zone is controlling that zone.
When communication resumes, the original cluster does not reform on its own, because both data centers have formed their own independent clusters. To reform the original cluster, you restart the master node for one of the clusters.
- If you restart the master node in the Boston data center, the cluster logic sees that the Seattle data center already has an elected master node, so the Boston cluster joins the Seattle cluster instead of forming its own. The Seattle master node then syncs its data with the Boston nodes in the cluster. The data sync overwrites the Boston data with the Seattle data. The result is that Boston data received during the communication failure is lost.
- If instead, you restart the master node in the Seattle data center, the cluster logic would see that the Boston data center already has an elected master node, so the Seattle cluster would join the Boston cluster. The Boston master node would then sync its data with the nodes in the Seattle cluster. That data sync would overwrite the Seattle data with the Boston data. In this case, the result is that Seattle data received during the communication failure is lost.
To preserve as much data as possible, instead of just reforming the original cluster by restarting one of the clusters, we recommend you perform the following two precautionary steps.
- When a communication failure occurs, change the target DCDs for the BIG-IP devices in the zone that did not include the original master node (Boston, in our example) to one of the DCDs in the zone that housed the original master node (Seattle, in our example).
- When communication is restored, in the zone that did not include the original master node (Boston, in our example), use SSH to log in to the master node as root, and then type bigstart restart elasticsearch , and press Enter. Restarting this service removes this node from the election process just long enough so that the original (Seattle) master node can be elected.
After you perform these two steps, all alerts are sent to nodes in the zone that contained the original master node. Then when communication is restored, the DCDs in the zone in which the master node was restarted (Boston) rejoin the cluster. The resulting data sync overwrites the Boston data with the Seattle data. The Seattle data center has the data that was collected before, during, and after the communications failure. The result is that all of the data for the original cluster is saved and when the data is synced, all alert data is preserved.




