Applies To:
Show Versions
BIG-IQ Centralized Management
- 5.1.0
Managing Event Logs for Access
How do I manage event logs with a Logging Node?
Viewing the event logs as implemented on BIG-IQ® eases browsing of system event logs, and provides a way to obtain useful insights regarding the activity on applications and/or servers. The BIG-IQ platform enables a single view of all filters and log entries (and details for each entry) from multiple BIG-IP® devices.
It also provides a more intuitive navigation path through the log items.
- Discover and activate a BIG-IQ Logging Node.
- License and provision a BIG-IQ Logging Node.
- Define an external machine to which periodic data snapshots are sent.
- Configure a BIG-IP system to collect event logs and send them to the BIG-IQ Logging Node. Part of this configuration includes a virtual server configured with a logging profile.
- Configure a logging profile on BIG-IQ, assign it to a virtual server, and deploy it to the
BIG-IP device that has been configured to collect log events.
A logging profile is used to determine which events the system logs, and where, and the format of these events. It then directs security events to a BIG-IQ Logging Node, and the BIG-IQ system retrieves them from that node.
Logging Node uses a search engine that requires separate services for management and traffic. Keeping those services on separate networks reduces unnecessary congestion. The network designs described here are not required, but considered best practice.
BIG-IQ Networks
- A cluster management network to perform Elasticsearch configuration and status operations
- A cluster traffic network for inter-node communication
Logging Node Networks
- A cluster management network to perform Elasticsearch configuration and status operations
- A cluster traffic network for inter-node communication
- A listener network to handle inbound data traffic
This figure illustrates the network topology required to deploy a logging node for your event logs.
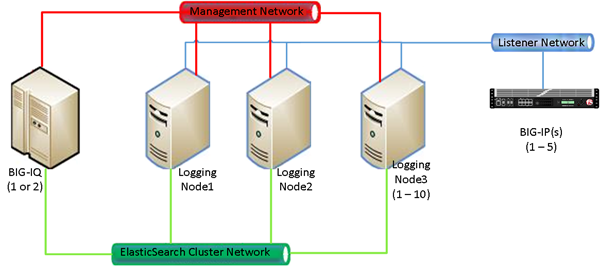
Logging Node network topology
What is a BIG-IQ Logging Node?
A BIG-IQ Logging Node is a specially-provisioned BIG-IQ® system, that runs the same software version as the BIG-IQ device that you use to manage your security, and the rules that determine your alert responses. After you provision the BIG-IQ Logging Node, you discover it from BIG-IQ and then add the service. Once you configure a logging profile, the Logging Node stores events related to security and application policies from one or more BIG-IP® systems. The BIG-IQ system can then retrieve and manage those logging events.
Discover and activate a logging node
Modifying event log indices
Define event snapshot storage locations
- storage-machine-IP-address
- storage-file-path
- Read/Write permissions for the storage file path
You need snapshots of your alert data to perform software upgrades, hotfix upgrades, and to restore your .
When event snapshots are created, they need to be stored on a machine other than the Logging Node that stores the events. You define the location for the snapshot by editing the fstab file on your Logging Node machines and on the BIG-IQ® and HA peer devices.
Define Access snapshot schedules
How do I license and do the basic setup to start using a Logging Node?
The BIG-IQ® Logging Node runs as a virtual machine in supported hypervisors, or on the BIG-IQ 7000 series platform. You license the Logging Node using the base registration key you purchased. The base registration key is a character string that the F5 license server uses to provide access to Logging Node features.
You license Logging Node in one of the following ways:
- If the system has access to the internet, you can have the Logging Node contact the F5 license server and automatically activate the license.
- If the system is not connected to the internet, you can manually retrieve the activation key from a system that is connected to the internet, and transfer it to the Logging Node.
- If your Logging Node is in a closed-circuit network (CCN) that does not allow you to export any encrypted information, you must open a case with F5 support.
When you license the Logging Node, you:
- Specify a host name for the system.
- Assign a management port IP address.
- Specify the IP address of your DNS server and the name of the DNS search domain.
- Specify the IP address of your Network Time Protocol (NTP) servers and select a time zone.
- Change the administrator’s default admin and root passwords.
Automatically license BIG-IQ and perform initial setup
Manually license BIG-IQ and perform initial setup
Configuring remote logging
Restore event log snapshots
The BIG-IQ® user interface does not currently support restoring the event snapshots. However, if a logging node fails, you can manually restore the data up to the last snapshot.
Please note the following:
- The restore operation requires a down time during which no BIG-IQ or Logging Node work is performed.
- During the restore operation, no event data sent to the Logging Node is retained.
- The restore operation restores only the data from the time before the chosen snapshot was created. Data from the time that the chosen snapshot was created to the current time is not restored.
- Before initiating a snapshot restore, make sure that sufficient disk space is allocated to the /var folder on the device to which you are restoring the snapshot.
Logging Node management
There are a number of useful concepts to consider when you manage Logging Nodes for off-box log storage. This reference material might prove helpful in setting up and maintaining your Logging Node configuration.
Index rotation policy
The optimum settings used to configure your logging node indices depend on a number of factors. Some of the key factors are discussed here.
The system provides the ability to dynamically create new indices based either on a specified interval or on a specified size. The primary goal to consider when you make these decisions is how to maintain a maximum disk allocation for the Logging Node data while maintaining capacity for new data that flows in.
Secondary considerations include search optimization, and the ability to optimize old indices to reduce their size.
Generally, the best policy is one that does not create unnecessary indices. The more indices, the lower the overall performance, because your searches have to deal with more shards. For example, if a module knows that it has a low indexing volume (thousands/day) then it makes the most sense to have a large aggregation per rotation (5 days or 30 days). For components like Web Application Security that probably have high indexing volumes, it makes more sense to rotate every 8 hours (which reduces the number of retained indices).
Index rotation also allows changing sharding and replica counts by changing the template on a given index type. New indices created from that template will contain the new shard and replica count properties.
This table shows the default configuration values for each index running on the BIG-IQ®. These values are based on anticipated data ingestion rates and typical usage patterns.
| Component | Index Name | Minimum Number of Logging Nodes | Rotation Policy | Retained Index Count | Approximate time window | Size of /var file system |
|---|---|---|---|---|---|---|
| Access | access-event-logs | 2 | Time/5 days | 19 | 95 days | 500 GB |
| Access | access-stats | 2 | Time/5 days | 19 | 95 days | 500 GB |
| Web Application Security | asmindex | 5 | Size/100000 MB | 5 | N/A | 500 GB |
| FPS | websafe | 2 | Time/30 days | 100 | 8 years | 10 GB |
If multiple modules are running on a given Logging Node or if you have higher inbound data rates, you might have to adjust these values to keep the /var file system from filling up (there is a default alert to warn of this when the file system becomes 80% full).
The simplest resolution is to revise the retained index count; lowering this value will reduce the disk space requirements but it will also reduce the amount of data available for queries. For details on changing this setting, refer to Modifying event indices.
Logging Node sizing guide
Logging Nodes are specialized BIG-IQ® devices designed to provide sufficient CPU, memory, and disk capacity to store and search logging data from BIG-IP® devices. The underlying technology to provide these services is Elasticsearch. (Information about general Elasticsearch comments can be found on their website: https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html)
Logging Nodes managed by BIG-IQ provide an Elasticsearch (ES) cluster that can scale horizontally (more nodes = more capacity), but each node in that cluster has limits on disk space. To mitigate that, there are a number of configuration elements that control how much disk is used by the system.
Logging Node Minimum Recommended Configuration
| CPU | 8 Cores |
| Memory | 32 GB |
| Disk | 10 GB (/var file system ) |
The /var file system on the Logging Node (which includes ES data) is only 10GB in size. To store more data on the file system, you need to extend the size. Refer to Index rotation policy for details on managing the data requirements. Extending the file system to 500GB is straightforward, assuming overall disk allocation on the BIG-IQ virtual machine is adequate. Log in as root to the Logging Node, and run the following commands.
-
tmsh show sys disk directory
The system response will be similar to this:
Directory Name Current Size New Size -------------- ------------ -------- /config 1048576 - /shared 10240000 - /var 10485760 - /var/log 7168000 - -
tmsh modify sys disk directory /var new-size
500000000
tmsh show sys disk directory
The system response will be similar to this:
Directory Name Current Size New Size -------------- ------------ -------- /config 1048576 - /shared 10240000 - /var 10485760 500000000 /var/log 7168000 - - Reboot the system and then confirm the size disk size.
tmsh show sys disk directory
The system response will be similar to this:
Directory Name Current Size New Size -------------- ------------ -------- /config 1048576 - /shared 10240000 - /var 500003840 - /var/log 7168000 -
Logging Node Capacity
The following table is a very rough guide to how much data can be stored on a given Logging Node. The estimate assumes that the Logging Node has been configured to the recommended /var filesystem size. This size is outlined in the Index rotation policy. Because all indexes share the same filesystem, the approximate maximum documents per node estimate assumes no other indexes exist on that node.
| Module | Index name |
Average document size (bytes) |
Approximate maximum documents per node |
|---|---|---|---|
| Access | access-event-logs | 730 | 500GB / 730 = 700 million |
| Access | access-stats | 730 | 500GB / 730 = 700 million |
| ASM | asmindex | 1400 | 500GB / 1400 = 350 million |
| FPS | websafe | 1400 | 10GB / 1400 = 70 million |
Managing Configuration Snapshots
What is snapshot management?
You can manage configuration snapshots for the configurations you have created on the BIG-IQ® Centralized Management system. A snapshot is a backup copy of a configuration. Configuration snapshots are created manually. This type of snapshot does not include events.
Comparing snapshots
You can compare two snapshots, or compare a snapshot to the configuration on the BIG-IQ® Centralized Management system to view their differences.




